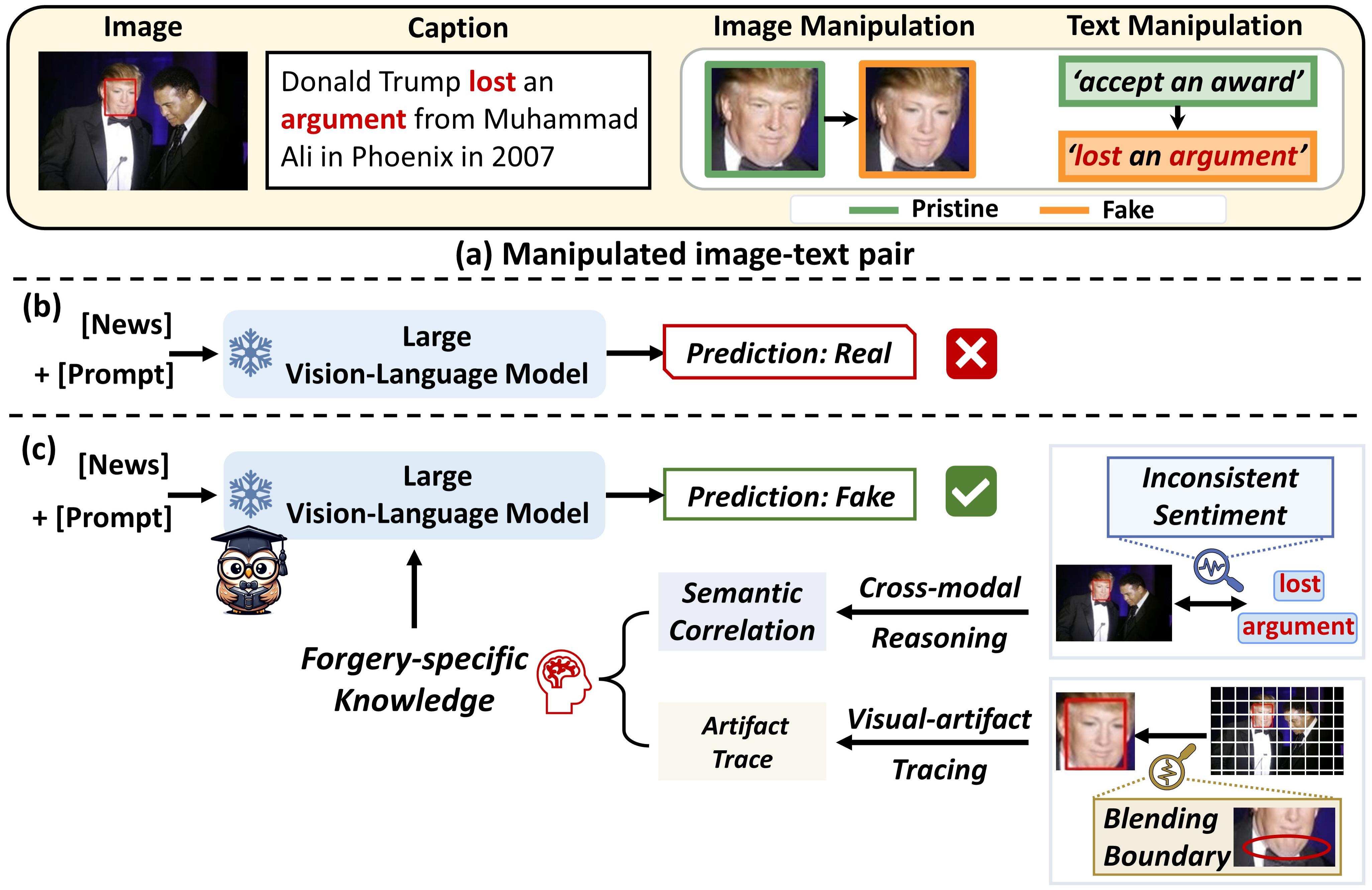
The massive generation of multimodal fake news involving both text and images exhibits substantial distribution discrepancies, prompting the need for generalized detectors. However, the insulated nature of training restricts the capability of classical detectors to obtain open-world facts. While Large Vision-Language Models (LVLMs) have encoded rich world knowledge, they are not inherently tailored for combating fake news and struggle to comprehend local forgery details.
In this paper, we propose FKA-Owl, a novel framework that leverages forgery-specific knowledge to augment LVLMs, enabling them to reason about manipulations effectively.
The augmented forgery-specific knowledge includes semantic correlation between text and images, and artifact trace in image manipulation. To inject these two kinds of knowledge into the LVLM, we design two specialized modules to establish their representations, respectively. The encoded knowledge embeddings are then incorporated into LVLMs.
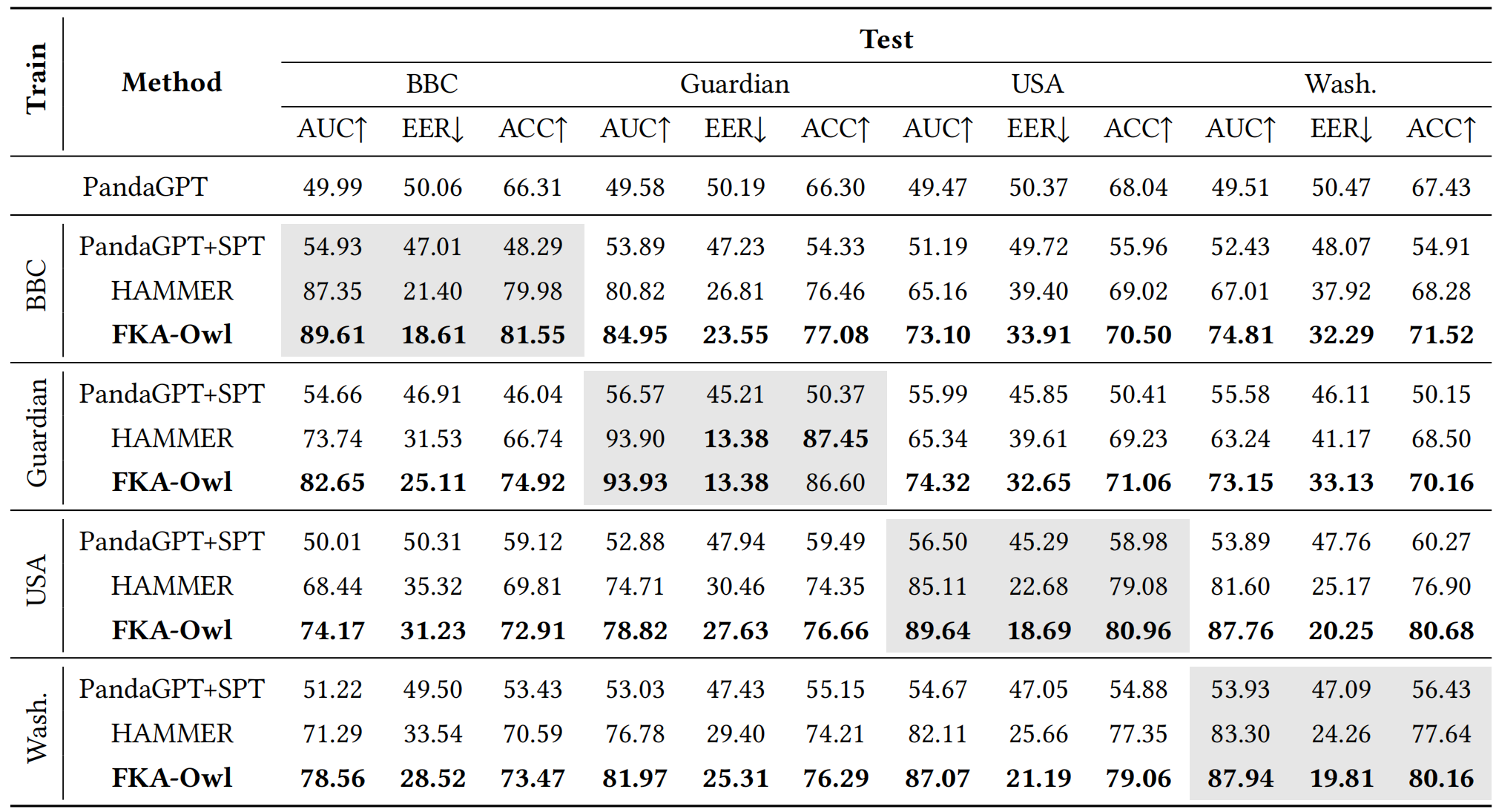
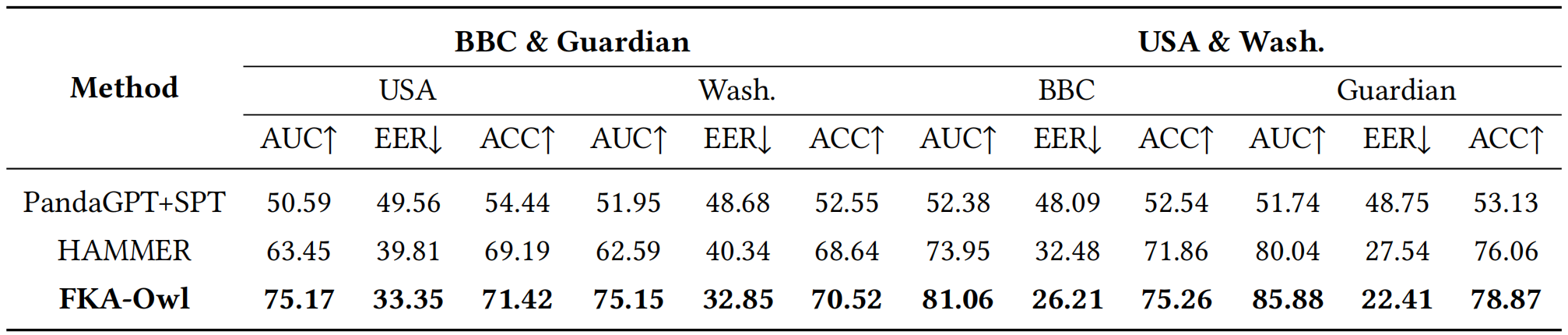
Extensive experiments on the public benchmark demonstrate that FKA-Owl achieves superior cross-domain performance compared to previous methods.
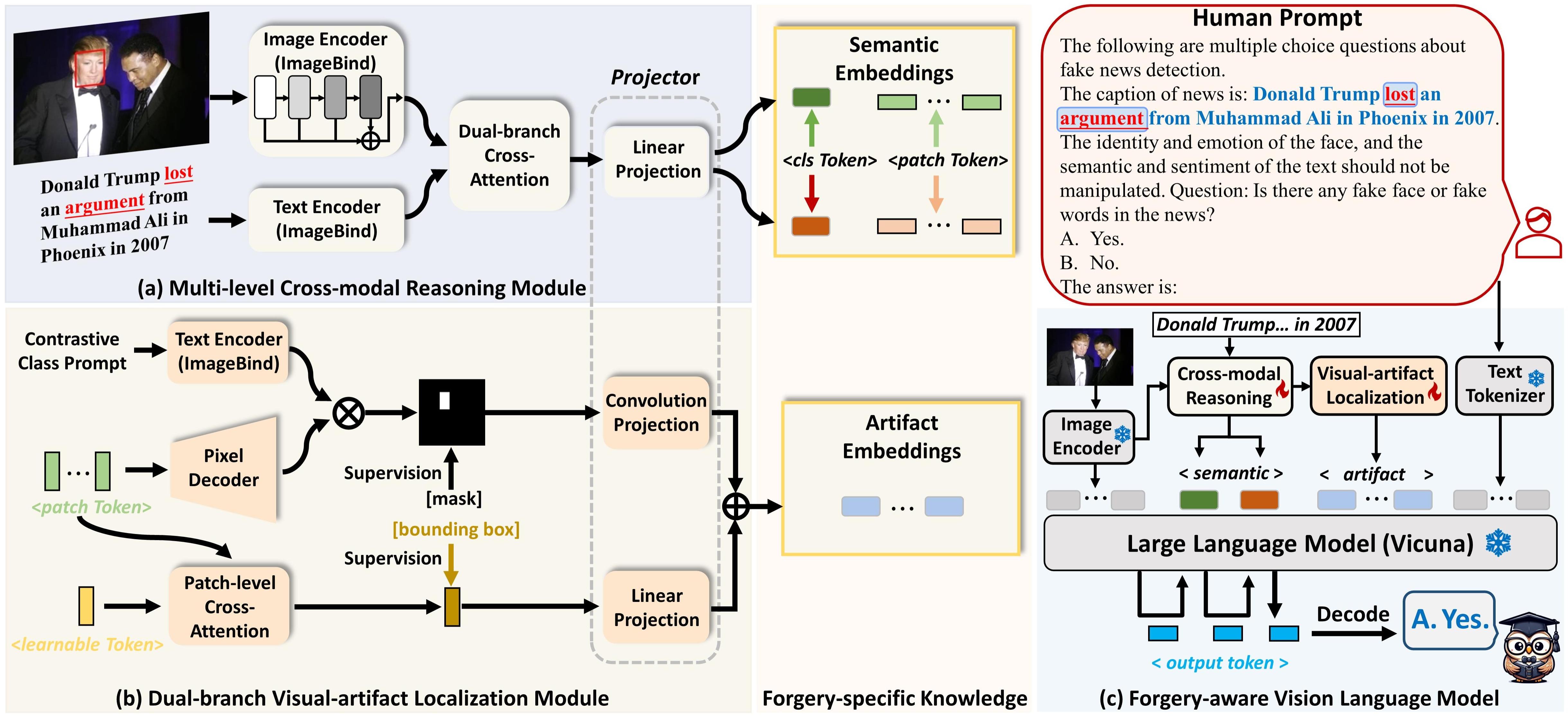
Our motivation is to leverage rich world knowledge from large vision-language models (LVLMs) and enhancing them with forgery-specific knowledge, to tackle the domain shift issue in multimodal fake news.
FKA-Owl consists of an image encoder (ImageBind), a cross-modal reasoning module, a visual-artifact localization module, and a large language model. The cross-modal reasoning module utilizes dual-branch cross-attention mechanisms to guide cross-modal interactions, facilitating the encoding of semantic embeddings. Concurrently, the visual-artifact localization module gathers local spatial information to establish artifact embeddings through supervised localization.
Subsequently, the encoded knowledge representation embeddings are mapped to the language space of LVLMs with projectors. We devise MFND instruction-following data for fine-tuning and employ both candidate answer heuristics and soft prompts to unleash the extensive knowledge of language models.
@inproceedings{liu2024fka,
title={FKA-Owl: Advancing Multimodal Fake News Detection through Knowledge-Augmented LVLMs},
author={Liu, Xuannan and Li, Peipei and Huang, Huaibo and Li, Zekun and Cui, Xing and Liang, Jiahao and Qin, Lixiong and Deng, Weihong and He, Zhaofeng},
booktitle={ACM MM},
year={2024}
}